Three ML breakthroughs that powered Mailchimp's design automation
As Mailchimp's dedicated machine learning R&D partner, Digital Scientists built three production neural network models, handwriting recognition, image saliency detection, and logo detection, that automated design personalization across millions of websites.
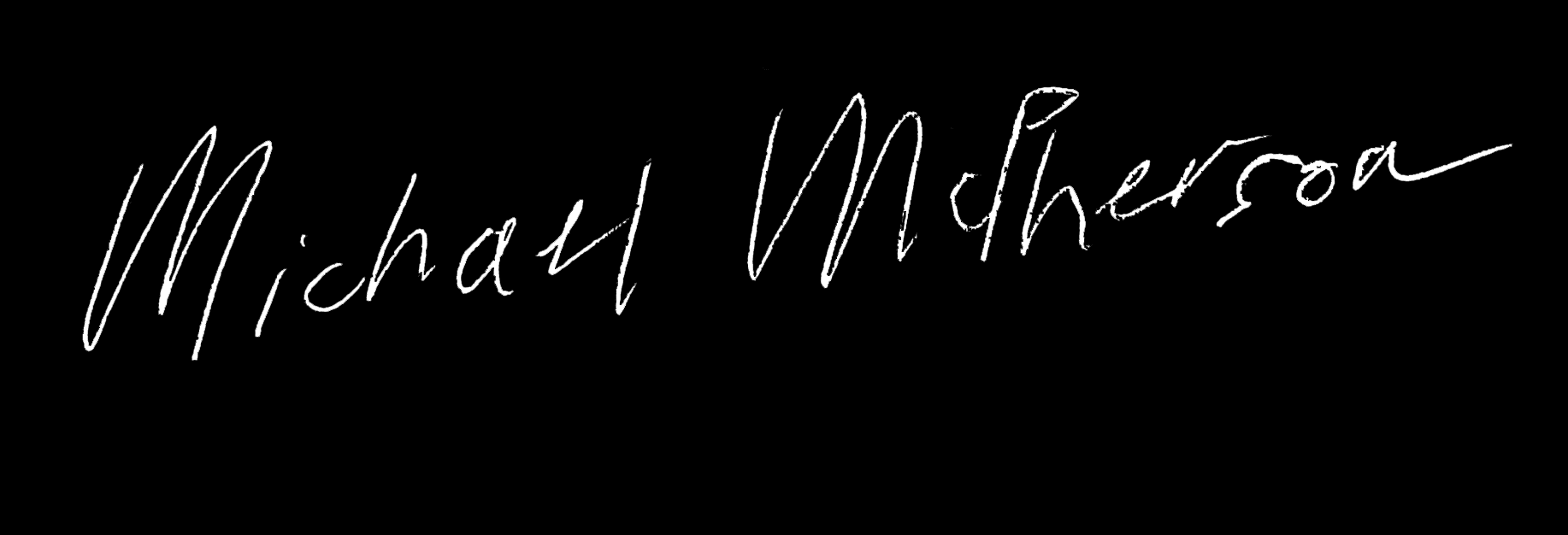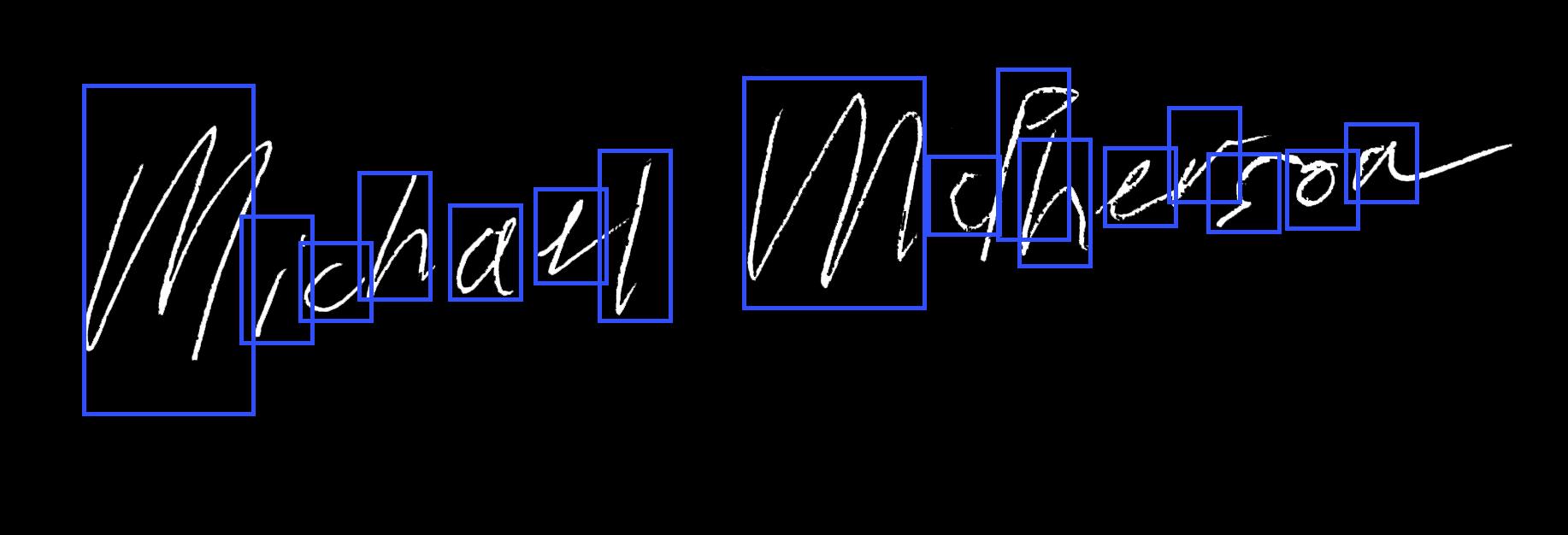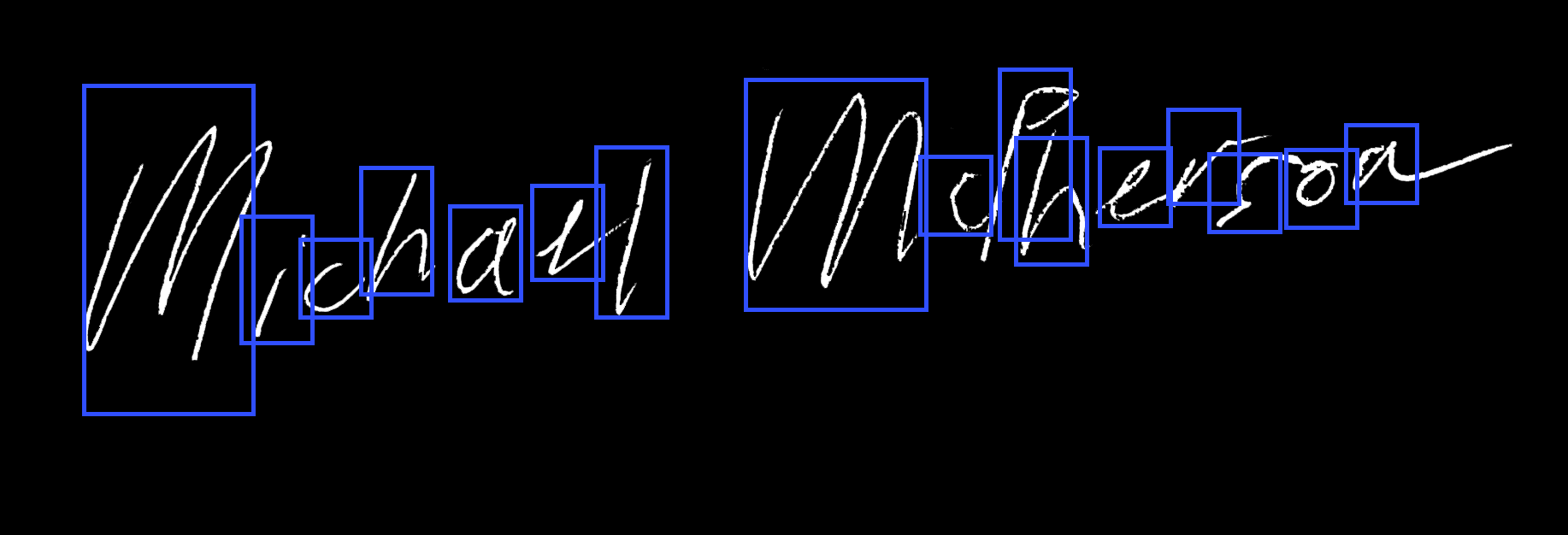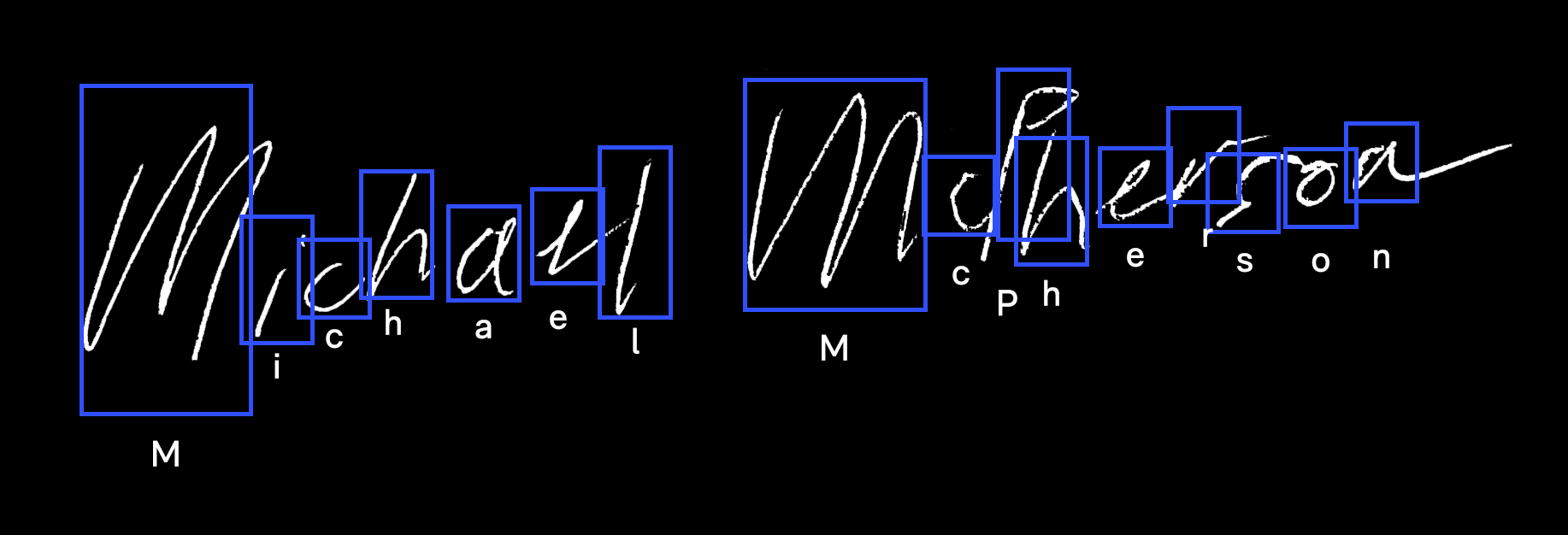
Handwriting Recognition Accuracy
Logo Detection Accuracy
Production ML Models
Neural Network Architectures
Mailchimp's dedicated ML R&D partner
Mailchimp, the global marketing automation platform, engaged Digital Scientists as their dedicated machine learning research and development partner. Across multiple engagements, our AI team tackled some of the most challenging problems in computer vision and natural language processing, building production-grade neural networks that powered Mailchimp's automated design services.
The partnership spanned three distinct ML projects, each addressing a different dimension of design automation: converting handwritten text to digital content, identifying focal points in images for intelligent cropping and overlay placement, and detecting and extracting brand logos from imagery. Each project required original research, custom training data generation, and novel neural network architectures.
Together, these models gave Mailchimp the ability to automate design personalization at scale, analyzing millions of websites and brand assets to deliver intelligent, AI-driven marketing tools to their users.
Handwriting analysis, reading handwritten text with deep learning
Converting handwritten script to typed text is one of the most vexing challenges in data science. Our team built a deep learning recurrent neural network (RNN) that achieves 85% accuracy on legible handwriting and 60% on poor handwriting.
The training data challenge
A neural network for handwriting recognition requires millions of handwriting samples as training data, a dataset that would take years to generate manually. Our AI experts took a highly innovative approach to solve this problem.
Instead of manual data collection, we used a combination of script typefaces from Microsoft, macOS, and Google as a starting point. We then randomized the rendering of each character, varying font, size, emphasis, and kerning within each word. To further imitate scribbled handwriting, we added noise to the letters, making them dirtier, fuzzier, and less legible.
The result was millions of messy character variations that could train our Long Short-Term Memory (LSTM) network to recognize real-world handwriting patterns.
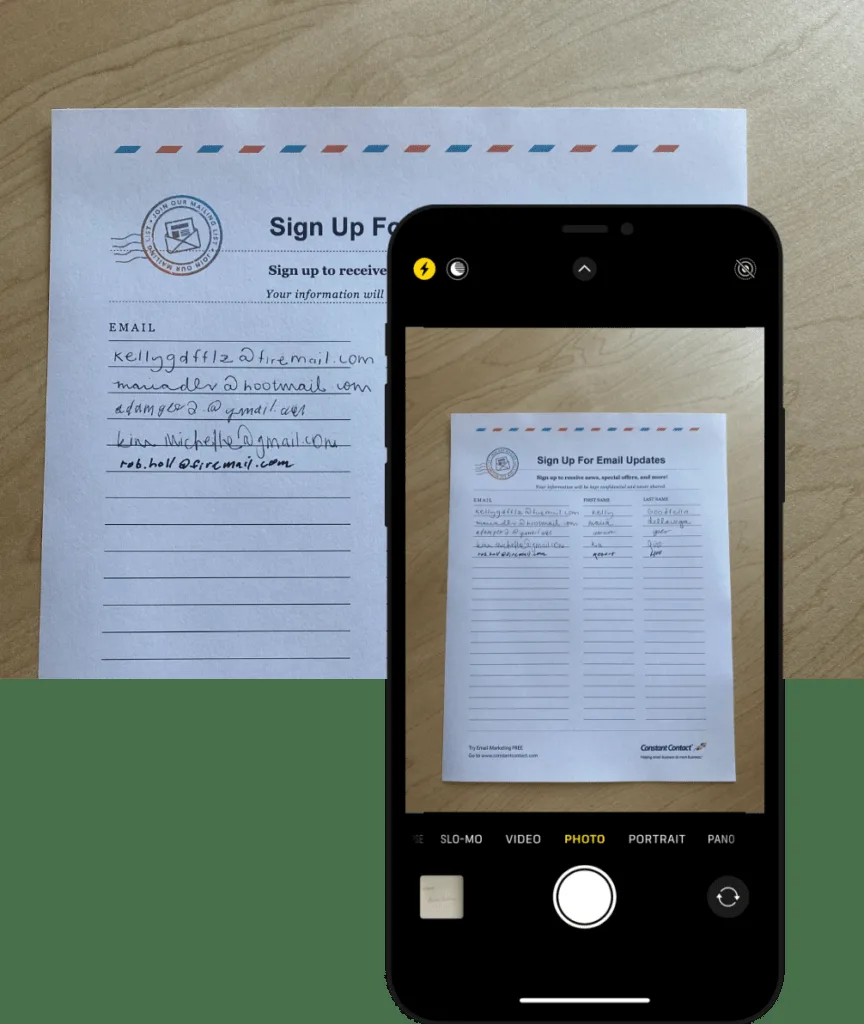

Pattern recognition at scale
By auto-generating an extensive training data set, our team applied a Long Short-Term Memory (LSTM) network to effectively read legible handwriting at an 85% success rate and poor handwriting at a 60% success rate.
Legible handwriting
Poor handwriting
Deliverables
- Trained LSTM neural network model
- Training data synthesizer
- API + source code
Image saliency detection, finding what matters most in any image
Mailchimp needed to identify the most salient visual elements, or focal points, within images across thousands of websites. Image saliency detection enabled AI-driven design automation to personalize marketing activities and provide automated design services.
Deep convolutional neural network
To automatically identify the most relevant visual elements within thousands of images, we used image saliency, a process that detects logos, branding, and other key design elements. The saliency map shows how a deep convolutional neural network (CNN) detects salient objects: the first image is the "input," the second is the "output."
Each image was analyzed using a deep convolutional network trained for saliency prediction. The resulting saliency data was split into four quadrants, analyzed independently to provide a saliency rating from 0 to 1. Lower saliency quadrants are generally better suited for asset overlays such as headings or logos.
We also calculated primary and secondary focal points to influence overlay positions and provide image cropping guidelines, ensuring that automated crops never lose the main crux of the image.


Guiding design decisions with ML
The saliency model answered three critical questions that power automated design placement:
- Can I place text here? Identifies low-saliency regions where overlays won't compete with important visual content.
- What is the focal point? Detects primary and secondary focal points to anchor design layouts.
- How should this image be cropped? Determines optimal crop boundaries based on quadrant brightness and saliency ratios.
Deliverables
- Trained CNN saliency model
- Quadrant saliency analysis
- Intelligent image cropping engine
Logo detection, extracting brand identity at 99% accuracy
Mailchimp needed the ability to extract logos and branding from random websites automatically. Through a custom CNN and a large training data set, we delivered a 99% accuracy rate in image classification, identifying logos, their placement, size, and prominence.
CNN-powered brand recognition
To distinguish branding from other images, our team developed an image recognition system built on a convolutional neural network (CNN). We created a large, purpose-built training data set and trained the network to classify images with 99% accuracy in Mailchimp's use case.
The system identifies logos and their placement, size, and prominence within any image. This enabled Mailchimp to auto-suggest logo placement and usage throughout their marketing application, enhancing the end-user experience.
Classification accuracy
Logo placement suggestions
From detection to automation
Thanks to this advanced automation, Mailchimp's end users can instantly extract logos from images, significantly boosting user productivity and enhancing the customer experience. The system received a significant "wow" response from Mailchimp's users.
By automating logo identification, the system auto-suggests logo placement and usage throughout Mailchimp's marketing application, further enhancing the end-user experience and driving increased revenue.
Deliverables
- Trained CNN classification model
- Purpose-built training data set
- Logo extraction + placement engine

The technology behind the models
Keras
High-level neural network API used to build, train, and iterate on deep learning models rapidly across all three projects.
TensorFlow
Production ML framework powering model training and inference at scale for handwriting recognition, saliency analysis, and logo detection.
OpenCV
Computer vision library for image preprocessing, segmentation, and feature extraction across the image analysis pipeline.
LSTM Networks
Long Short-Term Memory recurrent neural networks for sequential handwriting pattern recognition and character prediction.
CNN Architecture
Deep convolutional neural networks for visual pattern recognition, saliency mapping, and logo classification tasks.
Synthetic Data Generation
Custom data synthesizers that auto-generated millions of training samples, eliminating the need for manual data collection.
ML models powering design automation at scale
Across three R&D engagements, Digital Scientists delivered production-grade machine learning models that transformed Mailchimp's ability to automate design personalization. Each model solved a distinct challenge, together, they created a comprehensive AI-powered design toolkit.
Handwriting Recognition
LSTM neural network converts handwritten text to digital content using auto-generated training data, achieving 85% accuracy on legible and 60% on poor handwriting.
Image Saliency Detection
CNN-powered saliency analysis identifies focal points, guides intelligent image cropping, and determines optimal overlay placement for automated design.
Logo Detection & Extraction
CNN classification model extracts brand logos from imagery at 99% accuracy and auto-suggests logo placement throughout Mailchimp's marketing application.
Related case studies
Ready to build your ML-powered product?
From computer vision to NLP, Digital Scientists builds production-grade machine learning models that solve real business problems.